在 Ubuntu 上安装 NX 服务器
2013年01月24日 | 标签: linux, Mac, nomachine, nx, ubuntu
远程登陆 Linux 图形桌面有很多方式,比如使用 RFB (Remote Frame Buffer) 协议的各种 VNC 工具,TightVNC, UltraVNC, Xvnc 等,使用 NX 的 NoMachine, freenx, neatx 等。NX 通过 X11 调用来通信,比 VNC 这种通过截图似的通信要快的多,而且安全(通过 ssh),更适合在网速不高(相比局域网来说)的 Internet 上应用。如果你想在 VPS 上使用 Linux 图形界面的话,使用 NX 是一个比 VNC 好得多的方案。
安装 NX 服务器
到 NoMachine 官网下载 nxserver 4.0 到 Ubuntu 后直接安装就可以了,不需要其他的依赖包,这个比以前的 3.5 版本清晰多了,3.5 版本的 NX 服务器要装 nxnode, nxserver, nxclient,这三个名字很混淆人:
$ wget http://64.34.173.142/download/4.0/Linux/S/nxserver_4.0.181-7_i386.deb $ sudo dpkg -i nxserver_4.0.181-7_i386.deb
安装 NX 客户端
在 Mac 上下载 nx 客户端 nxplayer 4.0 后安装,需要注意的是,nxplayer 是 nxclient 的下一代版本,目前还是预览版,因为 Mac OS X 10.8 上不能使用旧版本的 nx 客户端(nxclient-3.5.0-7.pkg),安装后不能启动,所以这里只能用 nxplayer 预览版。
$ wget http://64.34.173.142/download/4.0/MacOSX/nxplayer-4.0.181-7.dmg
测试
安装完毕后,在 Mac 上启动一个 nxplayer 连接 Linux 上的 nxserver:
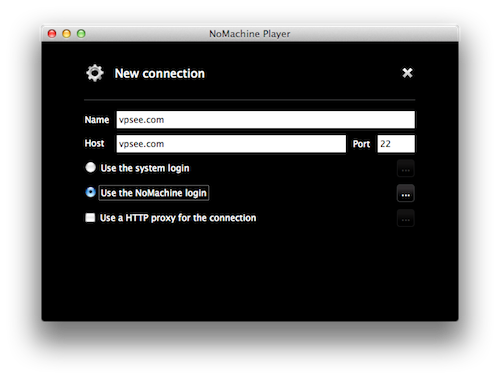
成功连接后输入用户名和密码就能进入 Ubuntu 桌面了: