把 Time Machine 备份到 FreeNAS 上
2013年02月7日 | 标签: freenas, Mac, mac os x, time machine
Mac 上的 Time Machine 很好用,不过每次备份都要用移动硬盘挺麻烦的。如果有多人使用多台 Mac 能不能把大家的 Time Machine 统一备份到云里或者局域网的某台服务器上呢?我们实验室大部分人都在用 Mac,现在正需要这么一个备份方案。谷歌了一下,发现这种使用 Time Machine 备份到远程电脑的方案是最方便、廉价的了,只需要一台普通 PC 就可以充当备份服务器。
Apple 使用自己的 Apple Filing Protocol (AFP) 协议提供文件共享服务,FreeNAS 刚好支持这一协议(貌似 Openfiler 目前还没有实现 AFP)。在一台服务器或虚拟机上安装 FreeNAS,安装过程很容易,这里省略。
配置 FreeNAS
安装好后进入 web 管理界面创建一个新用户,然后创建一个新 APF 共享, 在左边菜单里面选择 Sharing->Add Apple (AFP) Share,这里需要注意钩上 Disk Discovery 并选择 Disk discovery mode 为 Time Machine:
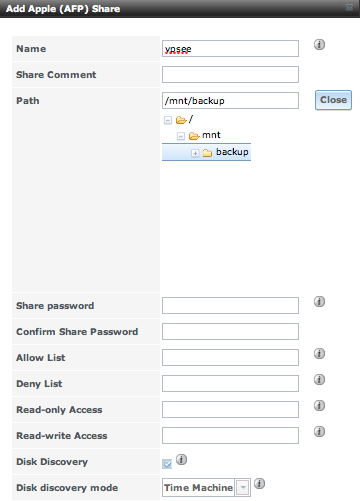
搞定~
配置 Mac
现在剩下的配置在 Mac 完成,让 Mac 连接刚创建的 AFP Share,点击 Mac 顶部菜单 Go->Connect to Server…,填入 freenas 服务器的 IP 地址 192.168.2.200 连接服务器:
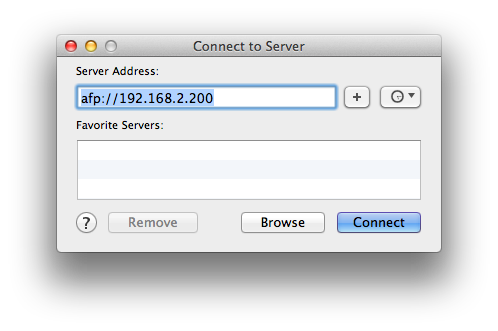
成功连接后会挂载一个 AFP share 盘,然后配置 Time Machine 选择这个盘当作备份盘:
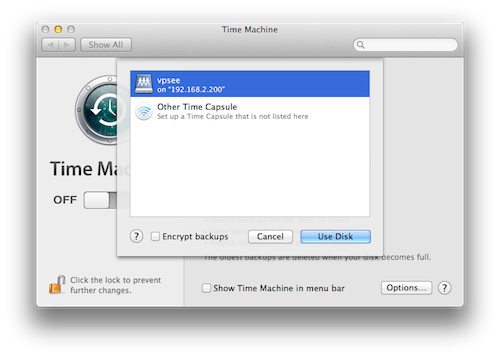
大功告成,等着自动备份吧: