Bash 通过上下键更有效的查找历史命令
2013年04月25日 | 标签: bash, history
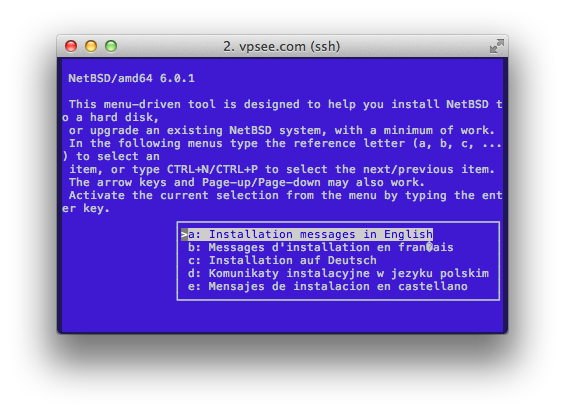
我们知道在 bash 里,可以通过 “上下” 键来浏览最近执行过的命令历史纪录(history),我们也知道如果历史纪录太多的话可以通过 ctrl+r 来查找命令或者通过 history 命令来浏览历史命令。我们不知道的是(也许只有本人不知道~),还有一种神奇的办法可以更准确、有效的在历史命令纪录中查找自己想要的命令。
在自己的用户主目录(home directory)新建一个 .inputrc 文件:
$ vi ~/.inputrc "\e[A": history-search-backward "\e[B": history-search-forward set show-all-if-ambiguous on set completion-ignore-case on
退出 bash 后重新登陆,敲打一个字母或者几个字母,然后 “上下” 键,就会看到以这个字母搜索到的完整命令行。如果搜索到几个类似命令,通过上下键来切换,有点像 ctrl+r,但是更好用。